Back to home page
This page demonstrates cooperative audio enhancement using a distributed array of 160 microphones spread throughout a large, reverberant room. Ten simultaneous speech sources were separated using different source separation techniques. The separated sources were used to calibrate real-time audio enhancement filters for each of four wearable listening devices, each with 16 microphones.
Reference: Ryan M. Corey, Matthew D. Skarha, and Andrew C. Singer, “Cooperative audio source separation and enhancement using distributed microphone arrays and wearable devices”, IEEE International Workshop on Computational Advances in Multisensor Adaptive Processing (CAMSAP), December 2019.
Dataset: Ryan M. Corey, Matthew D. Skarha, and Andrew C. Singer, Massive Distributed Microphone Array Dataset, University of Illinois at Urbana-Champaign, 2019. https://doi.org/10.13012/B2IDB-6216881_V1
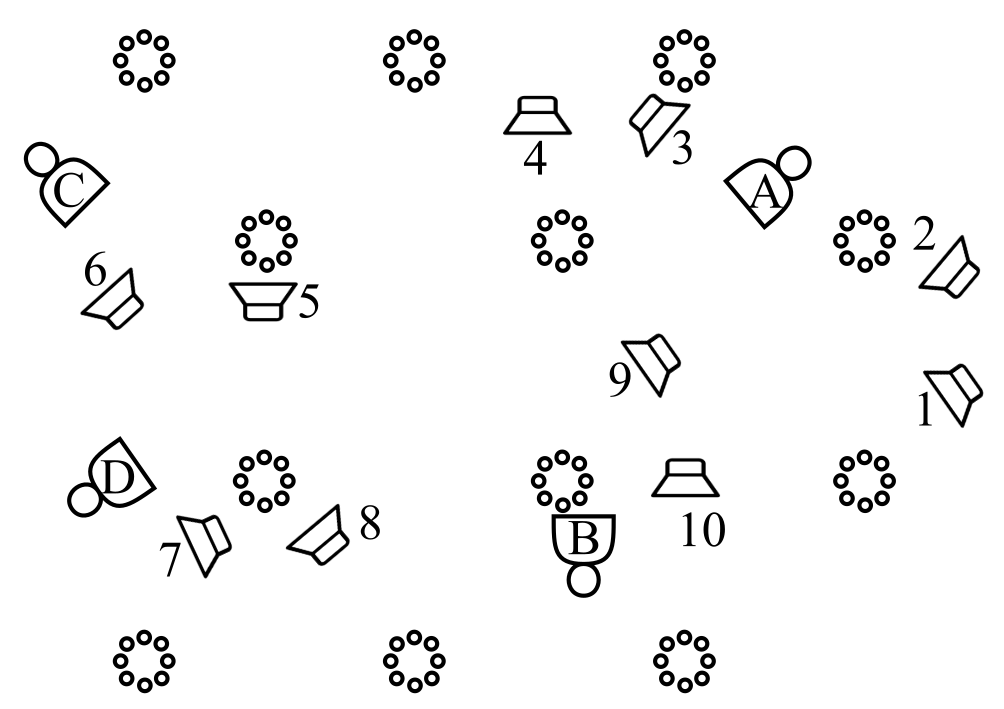
The speech data used in this experiment was taken from the VCTK corpus and played through ten loudspeakers in a large conference room. There were twelve 8-microphone tabletop arrays and four 16-microphone wearable arrays, as shown below.
 The first row of the table below presents the unprocessed ten-source mixture at the listener's ears. The second row contains binaural recordings of each source played alone. The remaining samples are from filters designed based on reference signals separated by the distributed array using an ideal unmixing filter, the unprocessed signal from nearest microphone to each source, and a blind source separation method initialized with the nearest-microphone signals. The enhancement filters use only the 16 microphones affixed to the listener's body.
The samples below represent the separated sources as captured by the microphones nearest the left and right ears. The clips are in stereo and best experienced using headphones. However, note that the mannequins have hollow heads and decorative ears and are not intended to provide realistic spatial cues.
The first row of the table below presents the unprocessed ten-source mixture at the listener's ears. The second row contains binaural recordings of each source played alone. The remaining samples are from filters designed based on reference signals separated by the distributed array using an ideal unmixing filter, the unprocessed signal from nearest microphone to each source, and a blind source separation method initialized with the nearest-microphone signals. The enhancement filters use only the 16 microphones affixed to the listener's body.
The samples below represent the separated sources as captured by the microphones nearest the left and right ears. The clips are in stereo and best experienced using headphones. However, note that the mannequins have hollow heads and decorative ears and are not intended to provide realistic spatial cues.