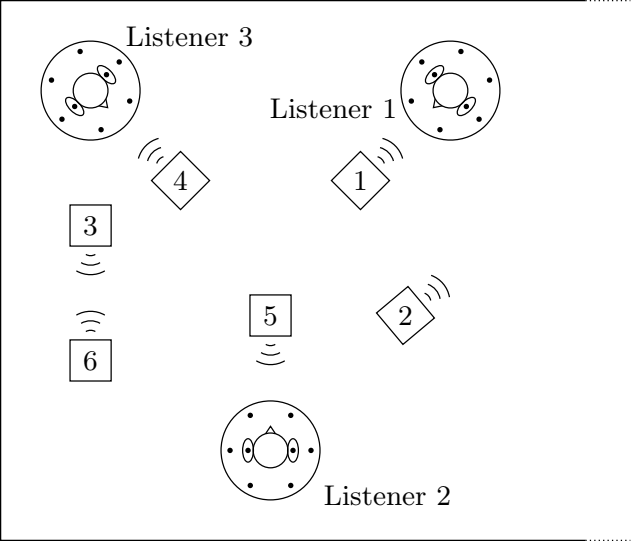
 The spatial statistics of each source were inferred from separate training recordings. These statistics were used to design four different source separation filters, shown in the table below. The first two rows are the unprocessed mixture and clean* source signals. The middle two rows are conventional static beamformers. The last two rows are the proposed time-varying source separation technique.
The samples below represent the separated sources as heard by Listener 2 (bottom left). The clips are in stereo and best experienced using headphones. Because the listener continuously moved his head up and down and from side to side during the recording, the sound sources should appear to move.
The spatial statistics of each source were inferred from separate training recordings. These statistics were used to design four different source separation filters, shown in the table below. The first two rows are the unprocessed mixture and clean* source signals. The middle two rows are conventional static beamformers. The last two rows are the proposed time-varying source separation technique.
The samples below represent the separated sources as heard by Listener 2 (bottom left). The clips are in stereo and best experienced using headphones. Because the listener continuously moved his head up and down and from side to side during the recording, the sound sources should appear to move.
| Array | Source 1 | Source 2 | Source 3 | Source 4 | Source 5 | Source 6 |
|---|---|---|---|---|---|---|
| Unprocessed | ||||||
| Clean* | ||||||
| Binaural pair, single listener | ||||||
| 8-microphone hat, single listener | ||||||
| Asynchronous binaural pairs, three listeners | ||||||
| Asynchronous 8-channel hats, three listeners | ||||||